
item 45 : 스트림은 주의해서 사용하라
스트림이란 자바 8부터 다량의 데이터 처리 작업(순차/병렬)을 돕고자 나온 API이며, 두 가지 핵심적인 추상 개념을 제공한다.
스트림은 원하는 결과를 생성하기 위해 파이프라인으로 연결될 수 있는 다양한 메서드를 지원하는 개체 시퀀스이다. 데이터의 흐름, 즉 스트림이 흘러가는 과정에서 데이터가 순차적으로 하나씩 사용되고 사라진다.
대용량 데이터를 처리할 때 효율을 높이기 위해, 오토박싱/언박싱 과정이 필요 없는 Intstream 과 같은 기본형 스트림도 제공한다.
스트림의 원소들은 어디로부터든 올 수 있 다. 대표적으로는 컬렉션, 배열, 파일, 정규표현식 패턴 매처(matcher), 난수 생성기, 혹은 다른 스트림이 있다.
스트림 안의 데이터 원소들은 객체 참조나 기본 타입값이다. 기본 타입 값으로는 int, long, double을 지원하는데 기본 타입의 경우 IntStream, LongStream, DoubleStream과 같은 Stream을 사용하는게 성능상 좋다.
Stream - 객체 참조에 대한 Stream
IntStream - int 타입에 대한 Stream
LongStream - long 타입에 대한 Stream
DoubleStream - double 타입에 대한 Stream
🔖 스트림의 추상 개념 1. 스트림(stream) : 데이터 원소의 유한 혹은 무한 시퀀스 2. 스트림 파이프라인(stream pipeline) : 이 원소들로 수행하는 연산 단계를 표현
🌱 스트림 파이프라인

이미지 분석
Stream Source: 배열, 컬렉션, I/O 채널 등 다양한 소스에서 스트림을 생성할 수 있음을 나타낸다.
Intermediate Operations: 필터링, 정렬, 타입 변환, 매핑 등의 중간 연산이 포함된다. 이 연산들은 스트림을 계속 반환하며, 메서드 체이닝 스타일로 연달아 적용할 수 있다.
Terminal Operation: 스트림을 소비하여 최종 결과를 반환하는 연산이다. 예를 들어
collect,sum,count와 같은 연산들이 있다.Operation Result: 최종 연산의 결과를 보여주는 부분

🌱 스트림 파이프라인 연산
스트림 파이프라인은 소스 스트림에서 시작해 종단 연산으로 끝나며, 그 사이에 하나 이상의 중간 연산이 있을 수 있다.
기본적으로 스트림 파이프라인은 순차적으로 수행되는데, 파이프라인을 병렬로 실행하려면 파이프라인을 구성하는 스트림 중 하나에
parallel 메서드를 호출해 사용하면 되긴하나, 효과를 볼 수 있는 상황은 많지 않다.
1. 중간 연산(Intermediate Operation)
각 중간 연산은 스트림을 어떠한 방식으로 변환하는 역할을 수행하며, 모두 한 스트림을 다른 스트림으로 변환하게 하여 메서드 체이닝을 가능하게 한다. 변환 된 스트림의 원소 타입은 변환 전 스트림의 원소 타입과 같을 수도 있고 다를 수도 있다. 예를 들어, 각 원소에 함수를 적용하거나 특정 조건을 만족 못하는 원소를 걸러낼 수 있다.
filter(),map(),sorted()
filter(Predicate<? super T> predicate)
지정된 predicate 함수에 맞는 요소만 스트림에 포함하도록 필터링
map(Function<? super T, ? extends R> function)
스트림의 각 요소에 function을 적용하여 새로운 요소로 변환
flatMap(Function<? super T, ? extends Stream<? extends R>> function)
각 요소에 function을 적용하여 생성된 스트림을 하나의 스트림으로 평탄화
distinct()
스트림의 중복 요소를 제거
sorted()
요소를 기본 정렬(오름차순)
sorted(Comparator<? super T> comparator)
지정된 comparator 함수를 사용하여 요소를 정렬
skip(long n)
스트림의 첫 n개의 요소를 건너뜀
limit(long maxSize)
스트림의 요소 중 최대 maxSize 개수만큼만 반환다.
2. 종단 연산(Terminal Operation)
종단 연산은 마지막 중간 연산이 내놓은 스트림에 최후의 연산을 가하는 역할을 한다.예를 들어, 원소를 정렬해 컬렉션에 담거나 특정 원소를 하나 선택하는 식이다.
forEach(),collect(),match(),count(),reduce()
Java Stream API의 추가 메서드와 설명을 표로 정리했습니다.
forEach(Consumer<? super T> consumer)
스트림의 각 요소를 consumer에 전달하여 순회하며 소비한다.
count()
스트림 내의 요소 개수를 반환한다.
max(Comparator<? super T> comparator)
comparator를 사용하여 스트림 내의 최대 값을 반환한다.
min(Comparator<? super T> comparator)
comparator를 사용하여 스트림 내의 최소 값을 반환한다.
allMatch(Predicate<? super T> predicate)
스트림의 모든 요소가 predicate에 만족하면 true를 반환한다.
anyMatch(Predicate<? super T> predicate)
스트림의 요소 중 하나라도 predicate에 만족하면 true를 반환한다.
sum()
스트림의 요소 합계를 반환한다. (IntStream, LongStream, DoubleStream에 사용)
average()
스트림의 요소 평균 값을 반환한다. (IntStream, LongStream, DoubleStream에 사용)

Stream<Transaction> 생성: 다양한
Transaction객체들이 스트림에 포함되어 있다.filter단계:t -> t.getType() == Transaction.GROCERY조건을 만족하는Transaction객체들만 필터링하여Stream<Transaction>을 생성한다.sorted단계:Transaction객체들을 값 (getValue()) 기준으로 내림차순 정렬한다.map단계: 각Transaction객체의id만 추출하여Stream<Integer>로 변환한다.collect단계: 최종적으로collect(toList())를 사용하여List<Integer>로 결과를 수집한다.
결과적으로 이 스트림 작업은 특정 조건을 만족하는 트랜잭션을 필터링하고, 정렬한 후, ID만 수집하여 리스트로 반환하는 과정이다.
🌱 스트림 파이프라인 특징
1. 지연 평가(lazy evaluation)
지연평가는 종단 연산이 호출될 때 이뤄지며, 종단 연산에 쓰이지 않는 데이터 원소는 계산에 쓰이지 않는다. 이 한 지연 평가가 무한 스트림을 다룰 수 있게 해주는 열쇠다. 종단 연산이 없는 스트림 파이프라인은 아무 일도 하지 않는 명령어인 no-op과 같으니, 종단 연산을 빼먹는 일이 절대 없도록 하자.
먼저 지연이란 결과값이 필요할때까지 계산을 늦추는 기법을 의미한다. 이렇게 함으로써 어느 부분에서 가장 큰 이익을 얻을 수 있을까?
대용량의 데이터에서, 실제로 필요하지 않은 데이터들을 탐색하는 것을 방지해 속도를 높일 수 있다. 즉, 종단 연산에 쓰이지 않는 데이터 원소는 계산 자체에 쓰이지 않는다. 그리고 이것을
Short-Circuit방식이라 부른다.

https://www.logicbig.com/tutorials/core-java-tutorial/java-util-stream/short-circuiting.html Java Stream API에서 "Short-circuiting Operations"(단락 연산)
해석 전에 요소들을 봐보자,
단락 연산은 전체 스트림을 처리하지 않고도 조건에 따라 스트림 처리를 조기에 종료할 수 있는 연산을 의미한다.
Intermediate Operation (중간 연산):
limit(): 스트림에서 요소의 개수를 제한한다. 예를 들어limit(5)는 스트림의 처음 5개 요소만을 포함하는 새로운 스트림을 생성한다.limit()는 중간 연산으로 스트림을 계속해서 변환할 수 있다.
Terminal Operations (종결 연산):
findFirst(): 스트림의 첫 번째 요소를 반환한다. 조건에 맞는 첫 번째 요소가 발견되면 나머지 요소를 탐색하지 않는다.findAny(): 병렬 스트림에서는 첫 번째가 아닌 임의의 요소를 반환할 수 있다. 조건에 맞는 임의의 요소를 찾으면 스트림 처리를 종료한다.anyMatch(): 스트림의 요소 중 하나라도 조건을 만족하는지 검사한다. 조건에 맞는 요소가 발견되면 나머지를 확인하지 않고 종료한다.allMatch(): 스트림의 모든 요소가 조건을 만족하는지 검사한다. 하나라도 조건에 맞지 않는 요소가 있으면 스트림 처리를 종료한다.noneMatch(): 스트림의 모든 요소가 조건을 만족하지 않는지 검사한다. 하나라도 조건에 맞는 요소가 있으면 스트림 처리를 종료한다.
카테고리별 설명
Limiting a size:
limit()연산을 통해 스트림의 크기를 제한할 수 있다.Finding an element:
findFirst()와findAny()를 사용하여 특정 요소를 찾을 수 있으며, 요소를 찾으면 연산이 종료Testing a match:
anyMatch(),allMatch(),noneMatch()연산을 사용하여 조건에 맞는 요소가 있는지 확인할 수 있다.
스트림 파이프라인을 실행하게 되면, JVM 은 곧바로 스트림 연산을 실행시키지 않는다. 최소한으로 필수적인 작업만 수행하고자 검사를 먼저 하고, 이를 바탕으로 최적화 방법을 찾아내 계획한다. 그리고 그 계획에 따라 개별 요소에 대한 스트림 연산을 수행한다.
예를 들어, 10000 개의 데이터중에 길이가 5가 넘는 문자열에서 가장 알파벳순으로 앞에 있는 2개의 문자열만 가지고 오고 싶다고 하자. 지연 평가가 없이 순서대로 바로 동작했다면, 10000 개의 데이터를 모두 순회해야 했을 것이다.
하지만 어짜피 최종적으로 2개만 탐색하면 되는데 전체 데이터를 다 볼 필요가 있을까?
limit사용 O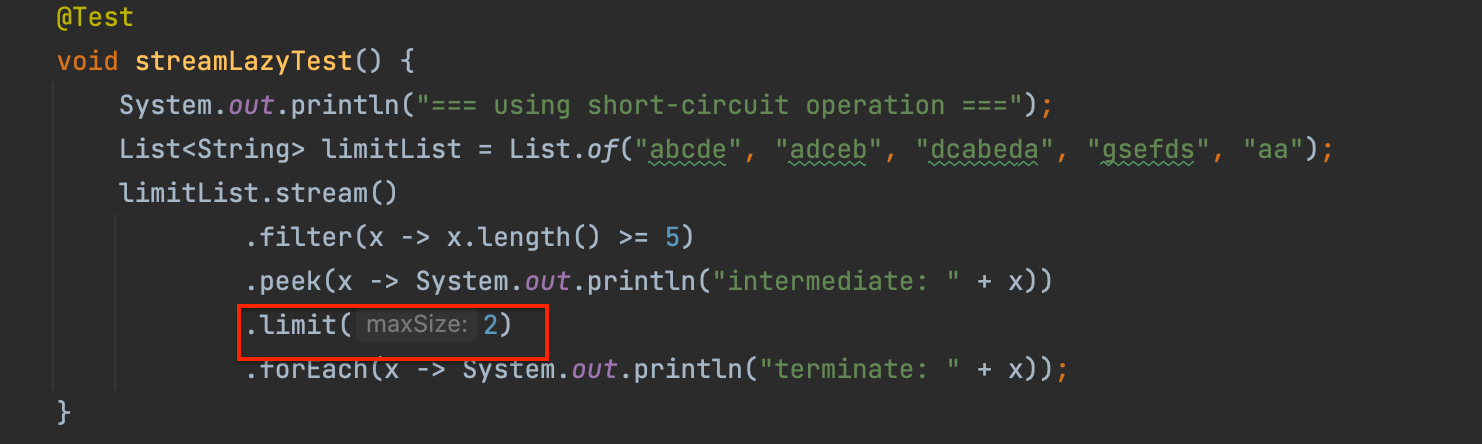
limit사용 X
결과를 봐보자. limit(n) 연산이 내부적으로 자신에게 도달한 요소가 n 개가 되었을 때 스트림 내 다른 요소들에 대해 더 이상 순회하지 않고 탈출하도록 만들었기 때문에, 길이가 5가 넘는 데이터 4 개가 아닌, 맨 앞에 2 개 데이터가 출력된 것을 볼 수 있다.

예외 사항: Stateful operations
이러한 지연 평가 특성으로 인해, 우리는 무한 스트림을 다룰 수 있게 된다.
무한 스트림은 애초에 크기가 정해져 있지 않은 만큼, 중복 제거를 하지 못한다 . 하지만 limit() 과 같은 short-circuit 연산을 통해 유한 스트림으로 변홤함으로써 가능해진다.
🔖 유한 스트림 vs 무한 스트림 1. 유한 스트림 : 생성할 때 크기가 정해져 있는 스트림
2.무한 스트림 : 무한한 크기로 값을 가지는 스트림
이처럼 중복을 제거하는 distinct() 나, 전체 데이터를 정렬하는 sort() 연산들을 Stateful 연산이라 한다. 하지만 이는 지연 평가를 무효화시키고, 결과를 생성하기 전에 전체 데이터를 탐색하는 결과를 초래한다. 예시를 봐보자.

limit() 을 걸어주었음에도, sorted() 으로 인해 길이가 5가 넘는 모든 네개의 데이터들을 탐색할 필요가 생겨 지연 평가가 이루어지지 않은 것을 볼 수 있다.

2. 순차성
기본적으로 스트림 파이프라인은 순차적으로 수행된다. 파이프라인을 병렬로 실행하려면, 파이프라인을 구성하는 스트림 중 하나에서 parallel 메서드를 호출해주기만 하면 되나, 효과를 볼 수 있는 상황은 많지 않다.
🌱 반복문을 스트림으로 무조건 바꾸는것이 좋을까?
스트림을 제대로 사용하면 프로그램이 짧고 깔끔해지지만, 잘못 사용하면 읽기 어렵고 유지보수가 힘들다. 그렇다면 방법은?
1. 모든 반복문을 스트림으로 바꾸기 보다, 반복문과 스트림을 적절히 조합하자.
다음 코드의 예시를 들어 설명해보겠다. 이 프로그램은, 사전 파일에서 단어를 읽어 사용자가 지정한 문턱값보다 원소 수가 많은 아나그램 그룹을 출력한다. (철자를 구성하는 알파벳이 같고 순서만 다른 단어)
computeIfAbsent(): 맵 안에 키가 있다면 매핑된 값을 반환하고 없다면 건네진 함수 객체를 키에 적용하여 값을 계산한 다음 키와 값을 매핑해놓고, 계산된 값을 반환
스트림을 과하게 활용하여, 사전 파일 여는 부분을 제외하고 프로그램 전체가 단 하나의 표현식으로 처리되고 있다. 이처럼 스트림을 과용하면 프로그램이 읽거나 유지보수하기 어려워진다.
스트림을 적절하게 활용하기
alphabetize() 과 같은 세부 구현은 주 프로그램 로직 밖으로 빼내 전체적인 가독성을 높였다. 이처럼 도우미 메서드를 적절히 활용하는 일의 중요성은 일반 반복 코드에서보다는 스트림 파이프라인에서 훨씬 커진다.
🔖 람다에서는 타입 이름을 자주 생략하므로, 매개변수의 이름을 잘 지어야 스트림 파이프라인의 가독성이 유지할 수 있다.
2.char 값을 처리할 때는 스트림을 사용하지 말자.
자바는 기본 타입인 char 용 스트림을 지원하지 않는다. 따라서 아래 코드를 실행시켜보면 정수값이 출력된다. 참고로 boolean[], byte[], short[], char[], float[] 도 해당 타입의 기본형 스트림이 존재하지 않는다.
🌱 스트림의 적절한 활용
스트림 파이프라인은 되풀이 되는 계산을 주로 함수 객체(람다/메서드 참조)로 표현하고 반복 코드에는 코드 블록을 사용해 표현한다.
스트림으로 처리하기 힘든 경우
스트림과 함수 객체로는 할 수 없지만, 코드 블록으로는 할 수 있는 경우를 구분하면 다음과 같다.
코드 블록에서는 범위 안의 지역변수를 읽고 수정할 수 있다. 하지만 람다에서는 사실상
final인 변수만 읽을 수 있고, 지역변수 수정은 불가능하다.코드 블록에서는
return/break/continue문으로 블록의 흐름을 제어하거나, 메서드 선언에 명시된 검사 예외를 던질 수 있다. 하지만 람다는 불가능하다.
스트림을 적용하기 좋은 경우
원소들의 시퀀스를 일관되게 변환해야 하는 경우 :
map()원소들의 시퀀스를 필터링 해야 하는 경우 :
filter()원소들의 시퀀스를 하나의 연산을 사용해 결합해야 하는 경우(더하기, 연결하기, 최솟값 구하기 등) :
원소들의 시퀀스를 컬렉션에 모으는 경우(공통된 속성을 기준으로) :
collect()원소들의 시퀀스에서 특정 조건을 만족하는 원소를 찾을 경우 :
filter()
🌱 스트림으로 처리하기 어려운 경우
한 데이터가 파이프라인의 여러 단계를 통과해야할때, 이 데이터의 각 단계에서의 값들에 동시에 접근하는 경우에는 스트림을 사용하기 힘들다. 파이프라인은 일단 한 값을 다른 값에 매핑하고 나면 원래의 값은 잃는 구조이기 때문이다.
🔖 핵심 정리 스트림과 반복 중 어느쪽이 나은지 확신하기 어렵다면, 둘 다 테스트해보고 더 나은 쪽을 택하는 것이 좋다.
출처 및 참고https://www.logicbig.com/tutorials/core-java-tutorial/java-util-stream/short-circuiting.html https://docs.oracle.com/javase/8/docs/api/java/util/stream/package-summary.html#Statelessness https://bugoverdose.github.io/development/stream-lazy-evaluation/
Last updated